

Hi, I'm Jiateng Liu.
I'm Jiateng Liu (刘嘉腾), a second-year Ph.D student at the University of Illinois Urbana-Champaign (UIUC) under the guidance of Prof. Heng Ji. Previously, I have spent two years in the group to earn my Master of Science degree. I earned my bachelor's degree in Computer Science from Zhejiang University. I have been fortunate to intern at Amazon as a applied scientist intern (Summer 2025) and Adobe Research as a research scientist intern (Summer 2026).
My research sits at the intersection of the Science of Large Models and their most exciting Applications. I began my research journey driven by a desire to understand how large models represent and propagate knowledge. But as foundation models have grown dramatically more powerful, I find myself increasingly drawn toward a different question: now that the base capability is here, what incredible new worlds can AI march into? The frontier is no longer just about making models better in the abstract—it's about deploying them and make them generalizable in rich, complex environments that were simply out of reach before: real-world business policies, physical assembly, and professional computer use My work reflects this shift: grounded in scientific rigor, yet pulled forward by the sheer breadth of what is suddenly possible.
Science: Understanding the internal mechanics of large models, how (multimodal) knowledge is stored, updated, and sometimes distorted, this gives us the leverage to build systems we can trust. I care about interpretability and robustness as foundations, not afterthoughts.
Applications: The world has opened up for AI in ways that feel almost vertiginous. I'm excited to be working on agents that operate real computers, robots that assemble physical objects from instructions, and systems that internalize the nuanced rules of real organizations. These are not toy problems—they are the next wave of AI's impact on daily life and work.
Research
My research is organized into three interconnected areas:

The Science of Language Models
Before we can reliably deploy AI, we need to understand its internal mechanics. I study how LLMs store, absorb, and propagate knowledge, and how that process breaks down. My work on knowledge editing (EVEDIT) introduces event-based boundaries that make knowledge updates deterministic rather than fragile, while work on knowledge overshadowing reveals systematic patterns behind LLM hallucination.
I view this line of research as the scientific foundation that keeps the applied work honest: understanding why models succeed or fail in the real world is what allows us to build systems we can actually trust.

MLLM Applications: Video Analysis and Assembly
As MLLMs become capable of rich visual and spatial reasoning, I'm excited to push them into domains that were previously out of reach. I worked in video analytics and now focuses a lot on Embodied AI Assistants for Assembly, where language and vision must translate into precise spatial understanding and produce physical actions.

LLM Agents: Bridging Language and Action
The central challenge for the next generation of AI agents is closing the gap between language-level reasoning and environment-specific execution. I pursue this along three directions: skill and action alignment, teaching agents not just how to act but why particular actions are appropriate, grounding language reasoning in the functional roles of tools and the consequences of actions; scalable agentic exploration, enabling agents to self-evolve their skill sets through active environment interaction and verifiable feedback, reducing reliance on human annotation; and automatic trajectory debugging, iteratively diagnosing failure modes in agent trajectories and refining the agent harness until tasks are reliably solved.
Publications

Brick-Composer: MLLMs Construct Everything from Building Blocks
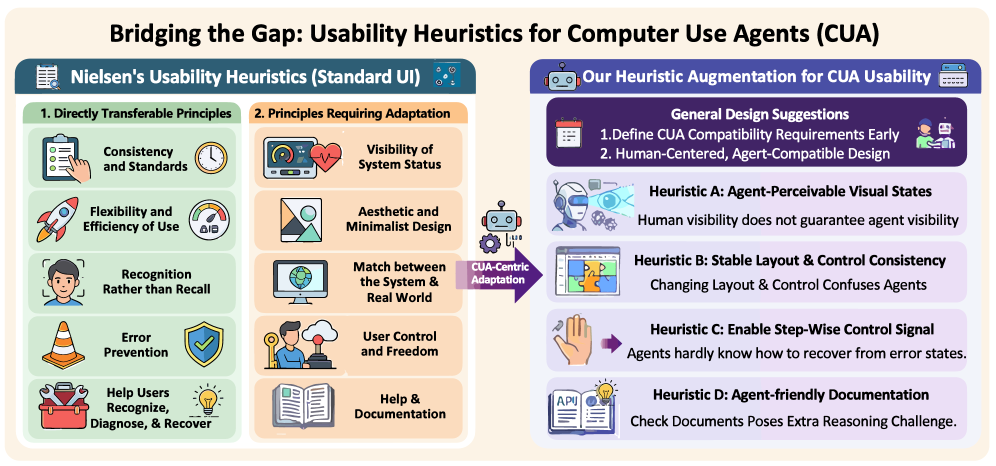
Augmenting Interface Usability Heuristics for Reliable Computer-Use Agents
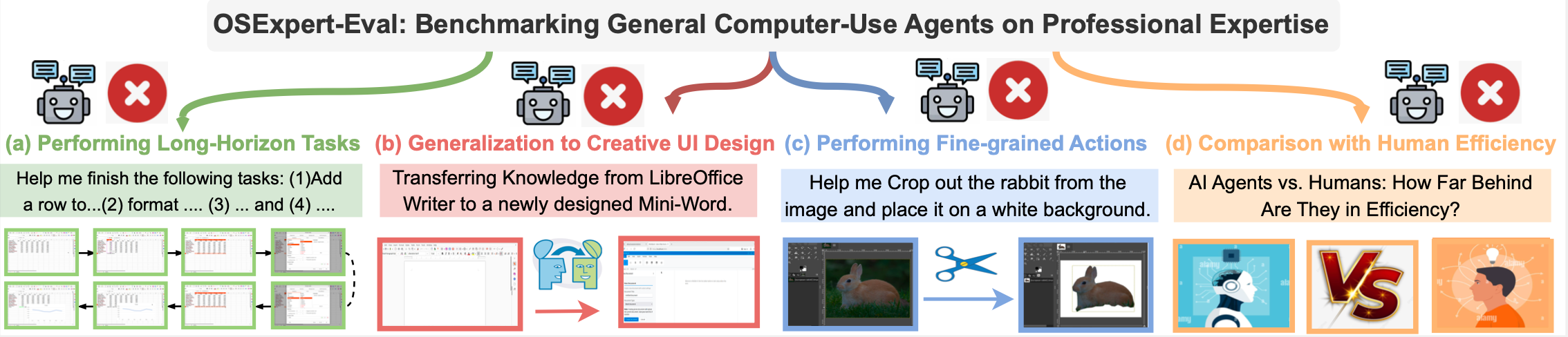
OSExpert: Computer-Use Agents Learning Professional Skills via Exploration

Analyzing and Internalizing Complex Policy Documents for LLM Agents
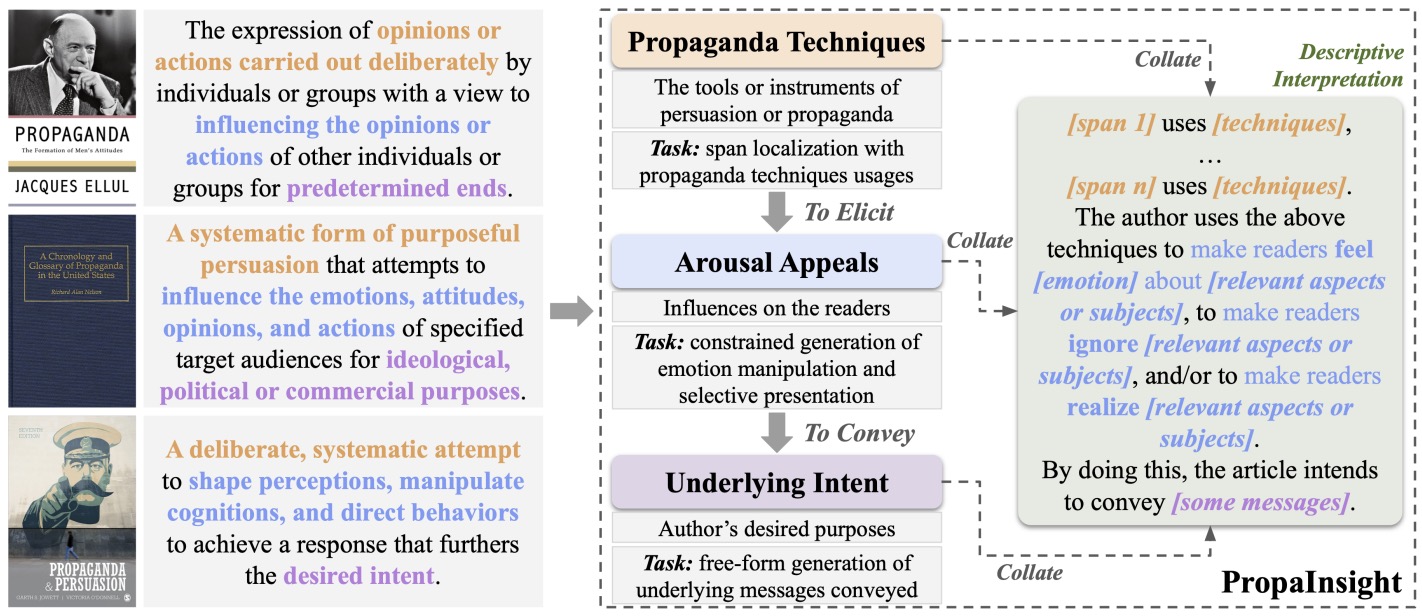


If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
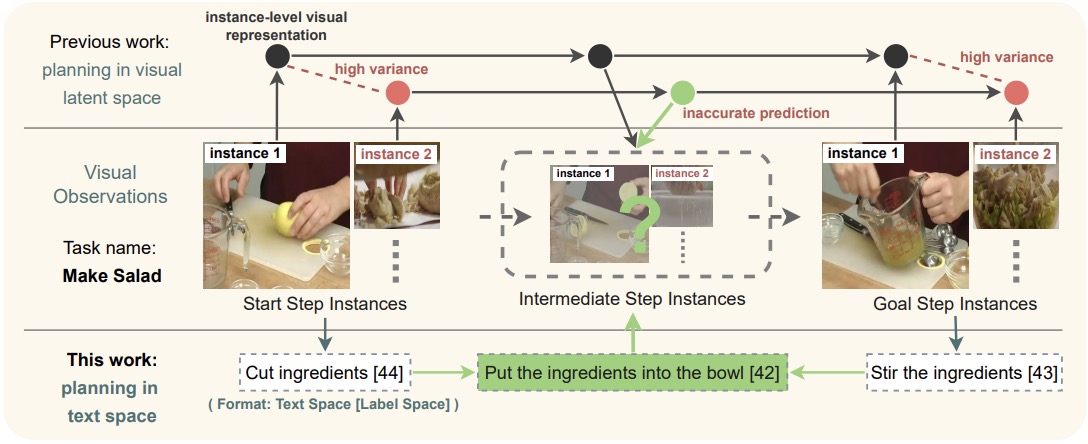

The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination

CurveCloudNet: Processing Point Clouds with 1D Structure

MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback
Industry Experience
- Research Intern at Adobe Research, mentored by Stefano Petrangeli, Yu Shen, and Saayan Mitra
- Applied Scientist Intern at Amazon Alexa AI team, mentored by Yingjie Li, Xiaojiang Huang, Xing Fan, Chenlei Guo, and Ruhi Sarikaya, managed by Xiang Li
Research Experiences
- 3D reconstruction with curve data
- Language side approaches for Procedure Planning
- Make Transformers efficient
- 3D Human mesh reconstruction
Assistantship
- Teaching assistant for CS440 at UIUC
- Research assistant of Prof. Heng Ji